# Replace the below parameters with the volume path you use.
CATALOG = "workspace"
SCHEMA = "default"
VOLUME = "default"
VOLDIR = "graphhopper"
volpath = f"/Volumes/{CATALOG}/{SCHEMA}/{VOLUME}/{VOLDIR}"
spark.sql(f"create volume if not exists {CATALOG}.{SCHEMA}.{VOLUME}")
!mkdir -p /Volumes/{CATALOG}/{SCHEMA}/{VOLUME}/{VOLDIR}Run GraphHopper on Databricks
Note that there is no particular advantage of running GraphHopper on Databricks, but if it is part of your larger workflow, then it is practical to keep this step in the same environment.
%sh
rm -rf ${VOLPATH}
mkdir ${VOLPATH}
cd ${VOLPATH}
wget -nv https://github.com/graphhopper/graphhopper/releases/download/8.0/graphhopper-web-8.0.jar
# example config, trace, and matching pbf
wget -nv https://github.com/graphhopper/graphhopper/raw/refs/tags/8.0/config-example.yml
wget -nv https://raw.githubusercontent.com/graphhopper/graphhopper/refs/tags/8.0/web/src/test/resources/issue-13.gpx
wget -nv https://download.geofabrik.de/europe/turkey-latest.osm.pbf
#edit config to match the pbf
sed -i "s|datareader\.file: \"\"|datareader.file: \"turkey-latest.osm.pbf\"|" config-example.yml
# note that this fails on many of the other gpx examples within the same folder, but that's a different problem.
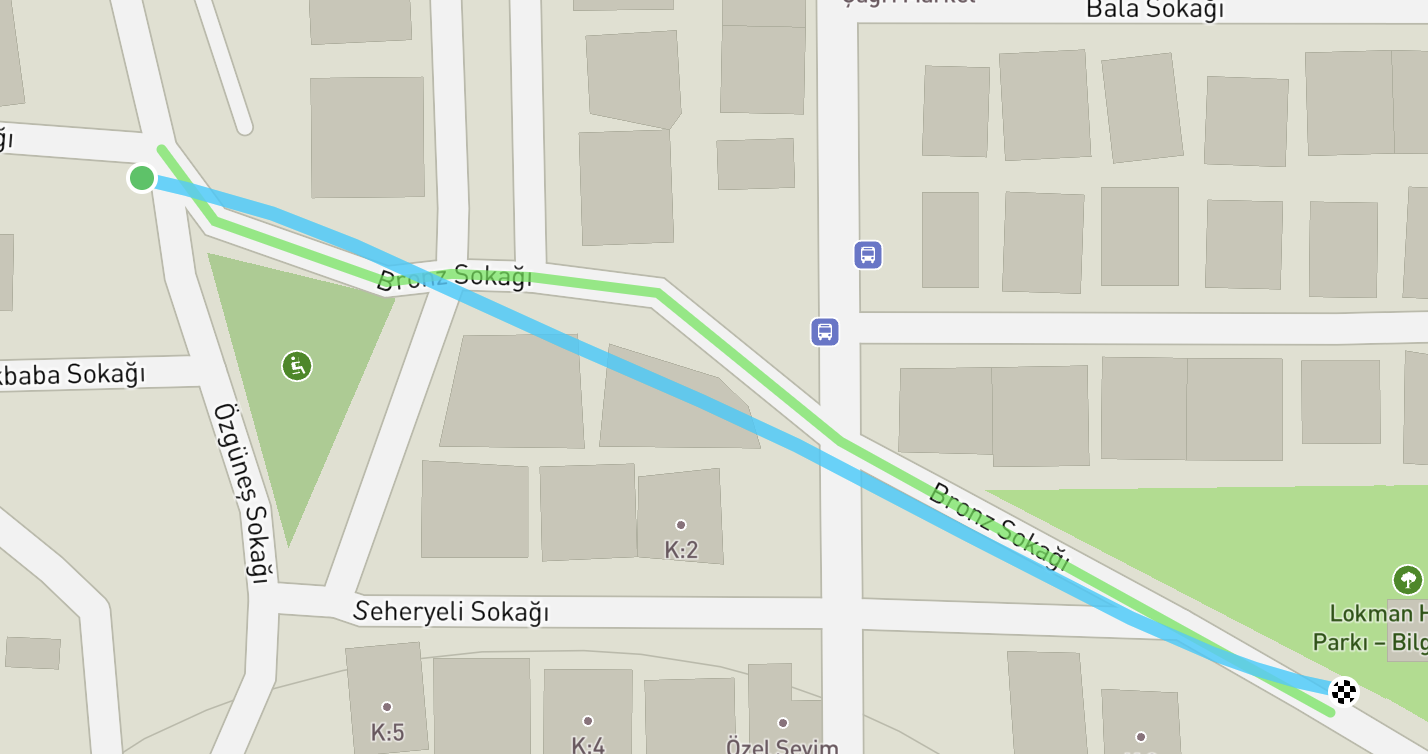
java -jar graphhopper-web-8.0.jar match --file config-example.yml --profile car issue-13.gpxVisualizing the generated GPX file with GPX Studio: